

One paper that caught my attention a bit ago was Selective attention in hypothesis-driven data analysis by Itai Yanai and Martin Lercher. In their study, students who were given specific hypotheses to test were much less likely to notice an obvious “gorilla in the data” compared to students who explored the data freely.
This is specifically what the data looks like:
data_m read_table("https://www.dropbox.com/s/685pkte3n3879mn/data9b_w.txt/?dl=1")
data_w read_table("https://www.dropbox.com/s/r3wyn2ex20glsoa/data9b_m.txt/?dl=1")
data_m data_m %>%
mutate(gender = "male")
data_w data_w %>%
mutate(gender = "female")
data bind_rows(data_m, data_w)data %>%
ggplot(aes(x = steps, y = bmi, color = gender)) +
geom_point()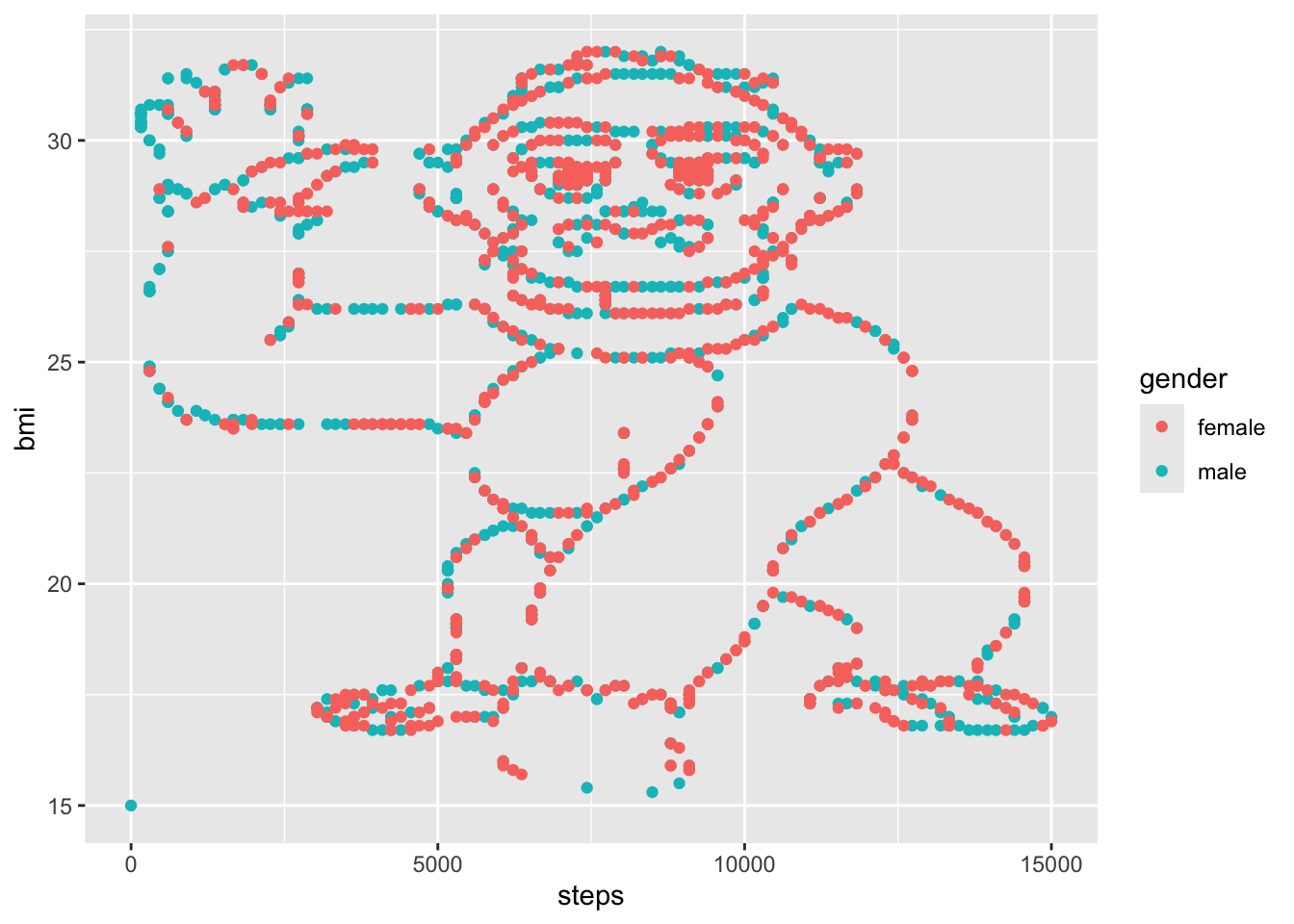
In this study, 119 of the 164 undergraduate students received the following instructions:
The remaining 45 students were provided these instructions:
I use large language models relatively often to assist with smaller portions of my daily bioinformatics work and have been interested in studying their ability to perform complete bioinformatics analyses. A key part of any analysis is exploratory data analysis (EDA), and I wondered how well large language models would perform at this task. This naturally begs the question: are large language models able to notice the “gorilla in the data” given the same prompts given to human students?
I decided to test this by asking both ChatGPT 4o (responses in green) and Claude 3.5 Sonnet (responses in orange) to examine the data using their data analysis tools. I ended up only asking the second question to both models.
ChatGPT 4o
ChatGPT 4o first provided these three plots:
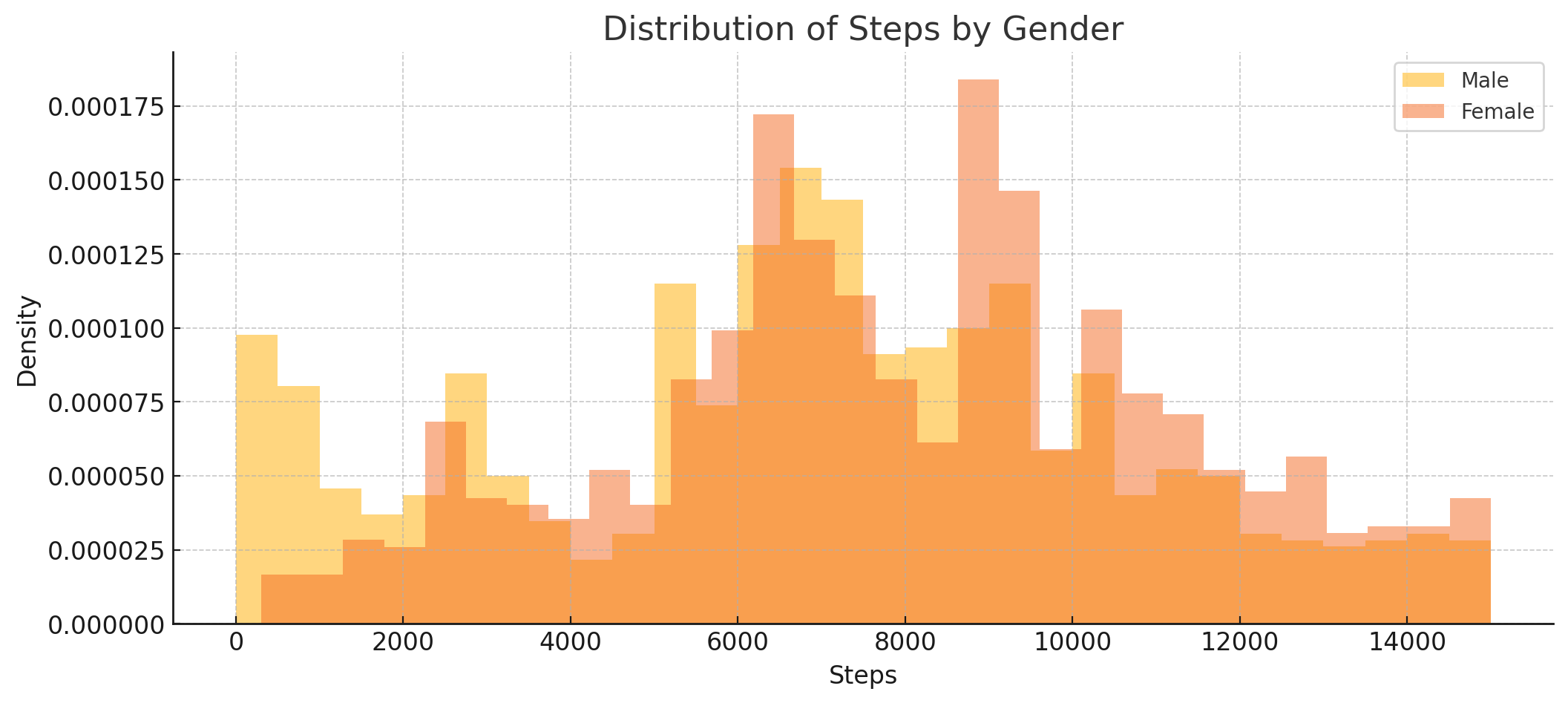
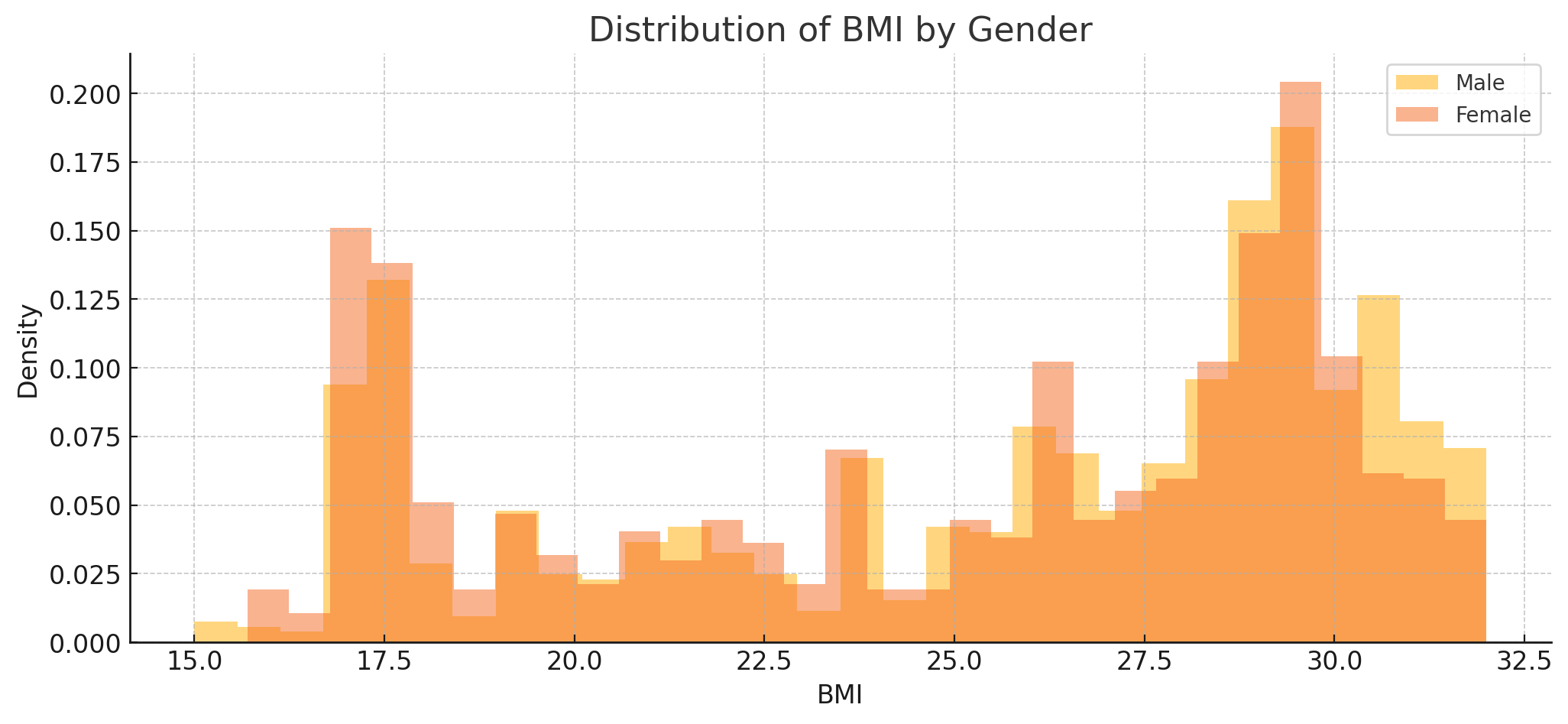
And provided this response:
The model seems to primarily focus on the data’s summary statistics. It makes some observations regarding the Steps vs BMI plot, but does not notice the gorilla in the data.
I asked the model to closely look at the plot, and also uploaded a png of the plot it had generated.
When a png is directly uploaded, the model is better able to notice that some strange pattern is present in the data. However, it still does not recognize the pattern as a gorilla. It again seems to want to prioritize certain quantitative analyses such as performing a correlation analysis.
Claude 3.5 Sonnet
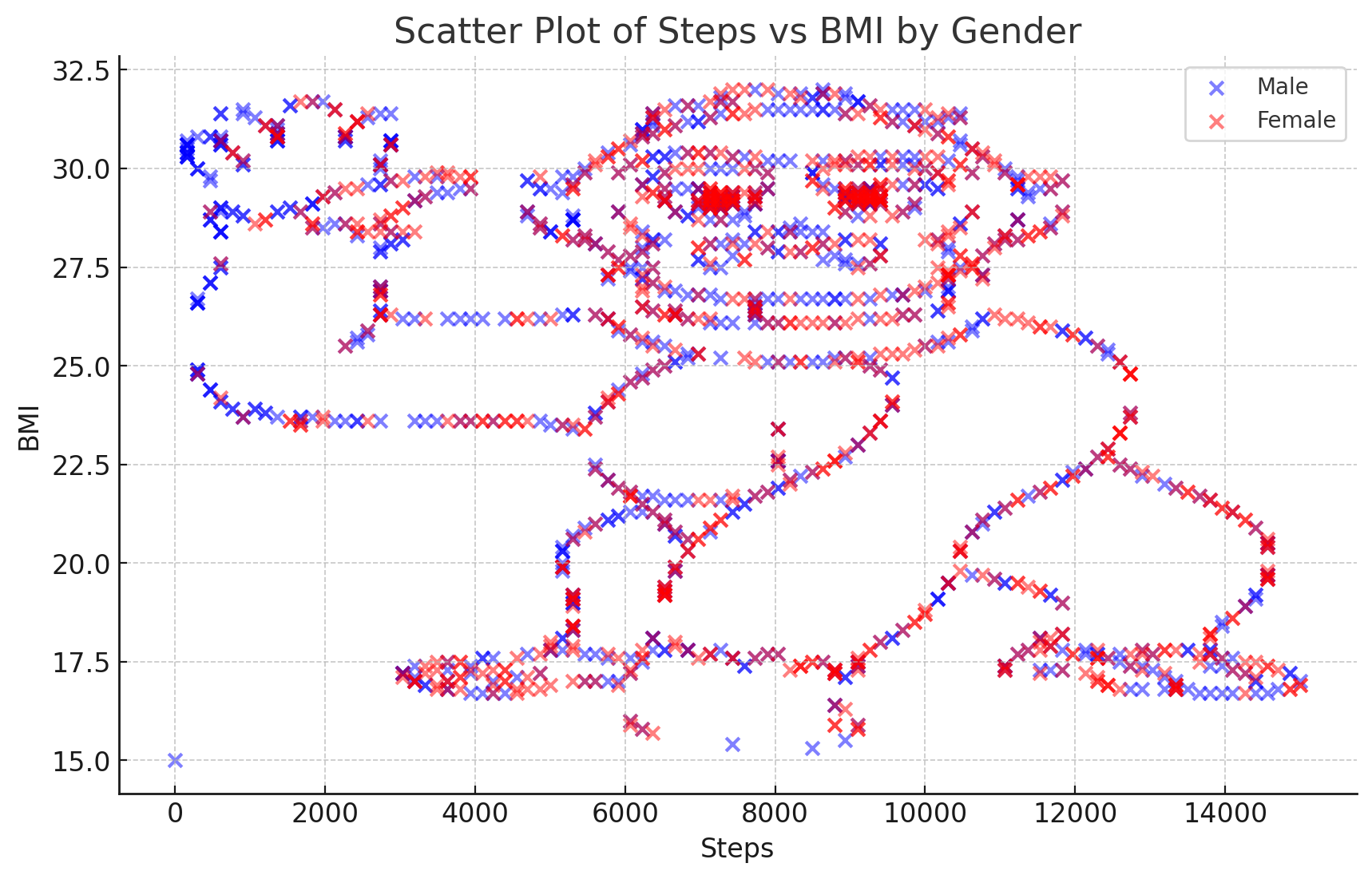
Claude 3.5 Sonnet provided this response:
And provided this dashboard:
Code
import React, { useState, useEffect } from 'react';
import { ScatterChart, Scatter, XAxis, YAxis, CartesianGrid, Tooltip, Legend, ResponsiveContainer, BarChart, Bar } from 'recharts';
import Papa from 'papaparse';
const BMIAnalysis = () => {
const [data, setData] = useState([]);
useEffect(() => {
const fetchData = async () => {
try {
const response = await window.fs.readFile('bmidata.csv', { encoding: 'utf8' });
const result = Papa.parse(response, {
header: true,
dynamicTyping: true,
skipEmptyLines: true
});
setData(result.data);
} catch (error) {
console.error('Error reading file:', error);
}
};
fetchData();
}, []);
const getBinData = (data, field, binSize) => {
const males = data.filter(d => d.gender === 'male');
const females = data.filter(d => d.gender === 'female');
const createBins = (items, field) => {
const min = Math.floor(Math.min(...items.map(d => d[field])));
const max = Math.ceil(Math.max(...items.map(d => d[field])));
const bins = {};
for (let i = min; i max; i += binSize) {
bins[i] = 0;
}
items.forEach(item => {
const binIndex = Math.floor(item[field] / binSize) * binSize;
bins[binIndex] = (bins[binIndex] || 0) + 1;
});
return Object.entries(bins).map(([bin, count]) => ({
bin: Number(bin),
male: items === males ? count : 0,
female: items === females ? count : 0
}));
};
const maleBins = createBins(males, field);
const femaleBins = createBins(females, field);
const combinedBins = {};
[...maleBins, ...femaleBins].forEach(item => {
if (!combinedBins[item.bin]) {
combinedBins[item.bin] = { bin: item.bin, male: 0, female: 0 };
}
combinedBins[item.bin].male += item.male;
combinedBins[item.bin].female += item.female;
});
return Object.values(combinedBins).sort((a, b) => a.bin - b.bin);
};
return (
div className="space-y-8">
div className="space-y-2">
h2 className="text-xl font-bold">BMI Distribution by Genderh2>
ResponsiveContainer width="100%" height={300}>
BarChart data={getBinData(data, 'bmi', 2)}>
CartesianGrid strokeDasharray="3 3" />
XAxis dataKey="bin" label={{ value: 'BMI', position: 'bottom' }} />
YAxis label={{ value: 'Count', angle: -90, position: 'insideLeft' }} />
Tooltip />
Legend />
Bar dataKey="male" fill="#8884d8" name="Male" />
Bar dataKey="female" fill="#82ca9d" name="Female" />
BarChart>
ResponsiveContainer>
div>
div className="space-y-2">
h2 className="text-xl font-bold">Steps Distribution by Genderh2>
ResponsiveContainer width="100%" height={300}>
BarChart data={getBinData(data, 'steps', 1000)}>
CartesianGrid strokeDasharray="3 3" />
XAxis dataKey="bin" label={{ value: 'Steps', position: 'bottom' }} />
YAxis label={{ value: 'Count', angle: -90, position: 'insideLeft' }} />
Tooltip />
Legend />
Bar dataKey="male" fill="#8884d8" name="Male" />
Bar dataKey="female" fill="#82ca9d" name="Female" />
BarChart>
ResponsiveContainer>
div>
div className="space-y-2">
h2 className="text-xl font-bold">Steps vs BMI Scatter Ploth2>
ResponsiveContainer width="100%" height={300}>
ScatterChart>
CartesianGrid strokeDasharray="3 3" />
XAxis type="number" dataKey="steps" name="Steps"
label={{ value: 'Steps', position: 'bottom' }} />
YAxis type="number" dataKey="bmi" name="BMI"
label={{ value: 'BMI', angle: -90, position: 'insideLeft' }} />
Tooltip cursor={{ strokeDasharray: '3 3' }} />
Legend />
Scatter name="Male" data={data.filter(d => d.gender === 'male')}
fill="#8884d8" />
Scatter name="Female" data={data.filter(d => d.gender === 'female')}
fill="#82ca9d" />
ScatterChart>
ResponsiveContainer>
div>
div>
);
};
export default BMIAnalysis;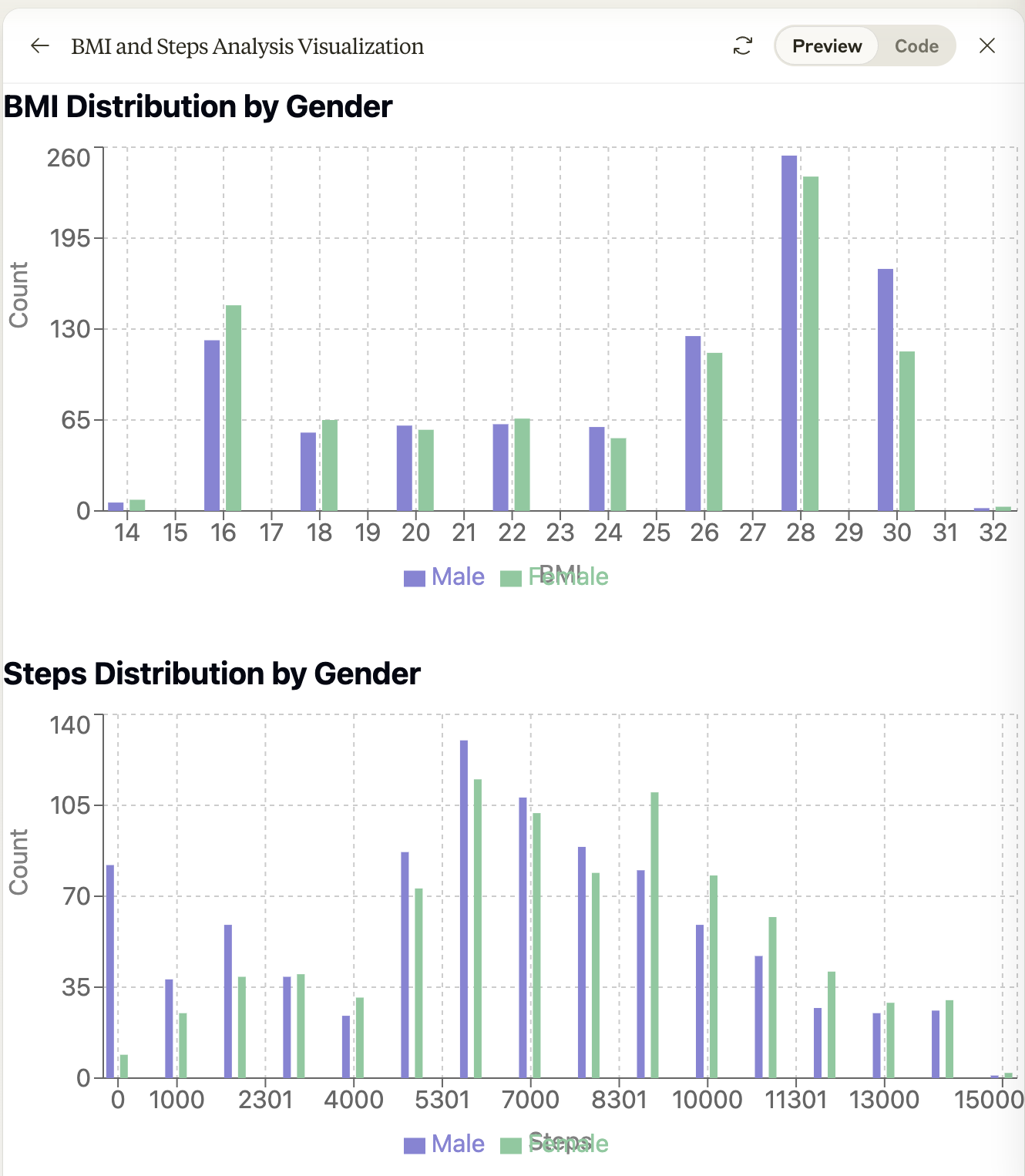
First, the model performs the analysis using javascript, which will probably make any bioinformatician shudder 🙈. Furthermore, the model is unable to notice obvious patterns in its visualizations, and seems to focus its analysis on the data’s summary statistics.
While the model can notice some sort of anomaly in the data, like 4o, it doesn’t seem to be able to notice the gorilla pattern from its own generated plot.
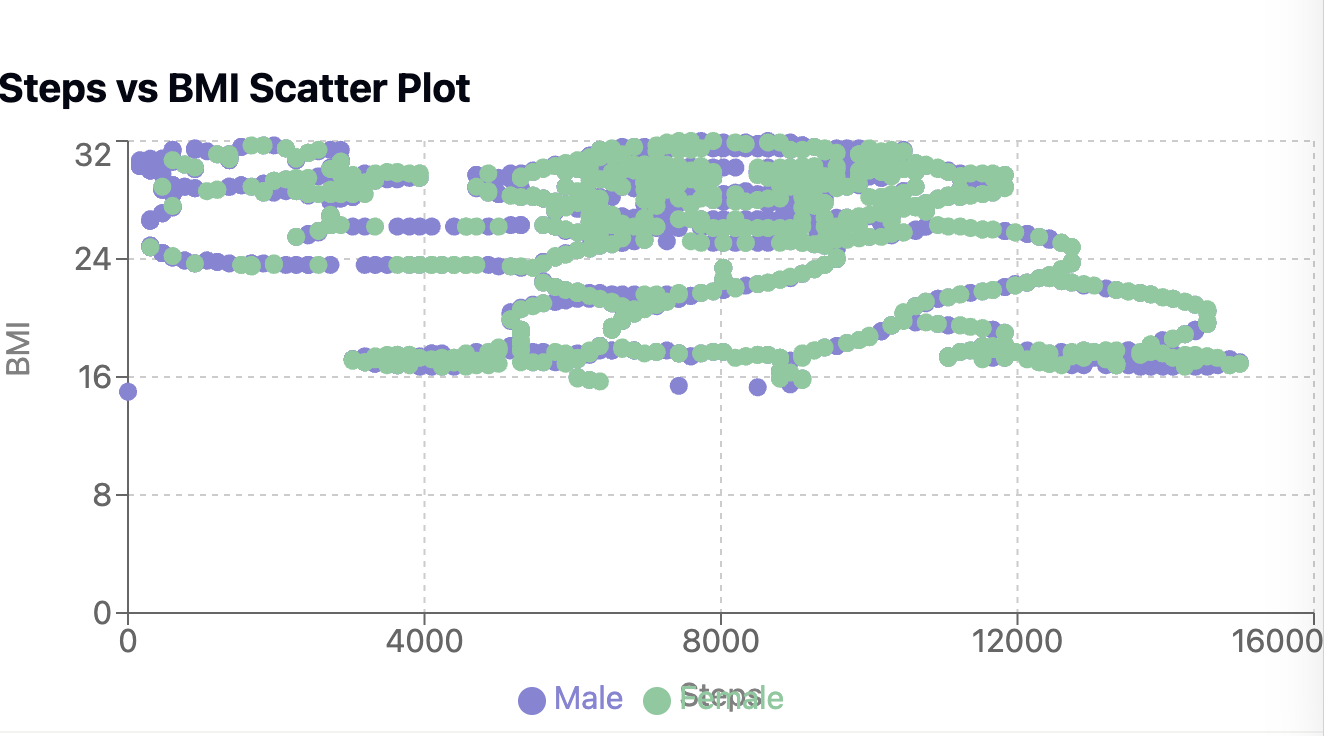
I then uploaded the BMI vs steps scatter plot from 4o (as I couldn’t easily export Sonnet’s plot) and asked the model to look at it.
Again, the model is able to notice the artificial patterns in the data when prompted to look at a png of the plot, but does not specifically understand the pattern as a gorilla.
Thoughts
As the idea of using LLMs/agents to perform different scientific and technical tasks becomes more mainstream, it will be important to understand their strengths and weaknesses. The most glaring current weakness, in my opinion, is the discrepancy between their pattern recognition capabilities when creating initial visualizations compared to when analyzing uploaded PNG files of visualizations. While these models do a good job of creating visualizations, they seemingly do not explicitly “see” them unless prompted. Furthermore, their data analysis capabilities seem to focus much more on quantitative metrics and summary statistics, and less on the visual structure of the data. In some ways, this could be seen as a feature rather than a bug. While humans are hard-wired to see faces in clouds and trends in random noise, these models appear to err in the opposite direction.
I have a few thoughts on potential implications:
First, it suggests that current LLMs might be particularly valuable in domains where avoiding confirmation bias is critical. They could serve as a useful check against our tendency to over-interpret data, especially in fields like genomics or drug discovery where false positives are costly. (But also it’s not like LLMs are immune to their own form of confirmation bias)
However, this same trait makes them potentially problematic for exploratory data analysis. The core value of EDA lies in its ability to generate novel hypotheses through pattern recognition. The fact that both Sonnet and 4o required explicit prompting to notice even dramatic visual patterns suggests they may miss crucial insights during open-ended exploration.
I’d next like to explore how to optimize these collaborative workflows and develop better prompting strategies for enhancing LLMs’ pattern recognition capabilities while preserving their resistance to cognitive biases, and also further understand what scientific biases they may introduce. I think that using LLMs as agents in bioinformatics workflows could speed up many repetitive tasks, but their behavior needs to be more deeply studied in this context.